

While I have dismissed Geekbench for showing a larger disparity in single core performance between Apple's A series and Intel's chips and brushing it off as Primate Labs optimizing better for Apple's SoCs over Intel's chips, I still wasn't really satisfied because well, that's an assertion with no real proof.
So Anandtech dug a little deeper into the design of the big cores of the A12: https://www.anandtech.com/show/13392/the-iphone-xs-xs-max-review-unveiling-the-silicon-secrets/3. This bit caught my attention:
QuoteMonsoon (A11) and Vortex (A12) are extremely wide machines – with 6 integer execution pipelines among which two are complex units, two load/store units, two branch ports, and three FP/vector pipelines this gives an estimated 13 execution ports, far wider than Arm’s upcoming Cortex A76 and also wider than Samsung’s M3. In fact, assuming we're not looking at an atypical shared port situation, Apple’s microarchitecture seems to far surpass anything else in terms of width, including desktop CPUs.
So for those keeping count, or not, the Vortex core can service 13 different operations at once, and those operations are:
- 6 integer operations (two of which are meant for more complex math operations)
- 2 Load/Store operations (this is literally as it says: loading or storing data)
- 2 branch operations (these apparently work on how branches should be taken)
- 3 FPU operations.
Compare this to the Cortex A75:
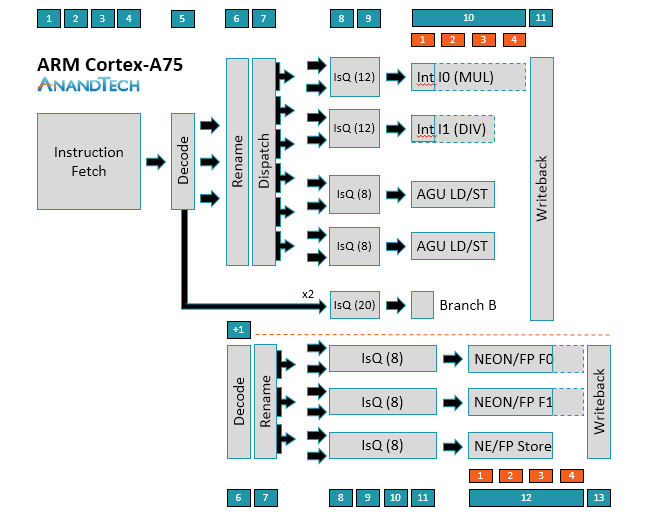
Which it looks like it can do:
- 2 integer operations
- 2 load/store operations
- 1 branch operation
- 3 FPU operations (though two that act on data, one that stores it)
So a total of 7 operations at once.
Compare this to Intel's Skylake:
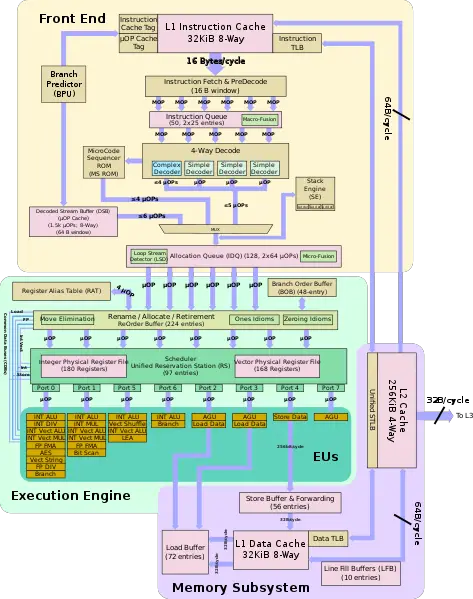
While it can do 8 operations at once, a majority of unique operations are contained within ports 0, 1, and 5. Ports 0 and 1 also do integer (both simple and complex) and FPU math.
And if we compare this to Zen:
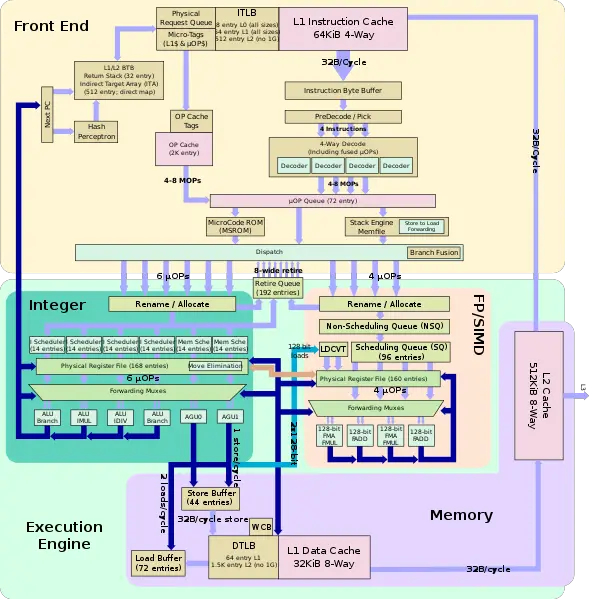
There's 4 integer operation ports (two can do complex, the other two can do branch), two load/store units, and four FPU units (though two are only FMA and FMUL, the other two are FADD). A total of 10 operations it can do at once.
Basically in short, it seems like Apple's design is about not trying to reuse ports as much as possible. I can imagine in certain workloads on Skylake's architecture there's a bottleneck because of the contention for using ports 0 and 1 if there's a lot of complex integer and FPU operations. Zen wouldn't have much of a problem here. Though if we're asking the CPUs to do everything, Apple would definitely win out here.
Still, I would like to see more than just GeekBench to corroborate this.
- ARikozuM, Dissitesuxba11s, Xiauj and 2 others
-
 5
5

-
.thumb.jpg.94f4ebc6714f0921314e56fdba4a05bf.jpg)
-

Apple's A12 can do 13 instructions at once. This could explain why it scores better in GeekBench
An Intel [whatever]lake can do only 8. And two of those are likely to cause execution bottlenecks.
-
-
No, because it depends on the instructions you're throwing at it and how the ports are allocated. If you do three instructions that hit the AGUs, Skylake is going to win out because everyone else only has two AGUs. If you throw a branch and two complex integer instructions, then Skylake loses. If you throw 10 of everything, then things get more interesting.
.thumb.jpg.94f4ebc6714f0921314e56fdba4a05bf.jpg)