
Is ARM Really More Efficient than x86-64, Or Is It Much More About Optimization From Top to Bottom

17 hours ago, linuxChips2600 said:we can't deny that computer parts, especially graphics cards, have become increasingly power hungry due to Dennard scaling (not quite but related to Moore's Law) breaking down around 2006 stemming from current leakages caused by quantum effects (e.g. quantum tunneling) at ever shrinking nodes.
No, not really. Dennard scaling refers to the performance per area of a single unit of computing. When talking about moderns CPUs, and specially GPUs, we're trying to push for more parallel compute power performance. GPUs in special have been relying on increased transistor density in order to fit more streaming units, and that's where most of the performance from each generation comes from.
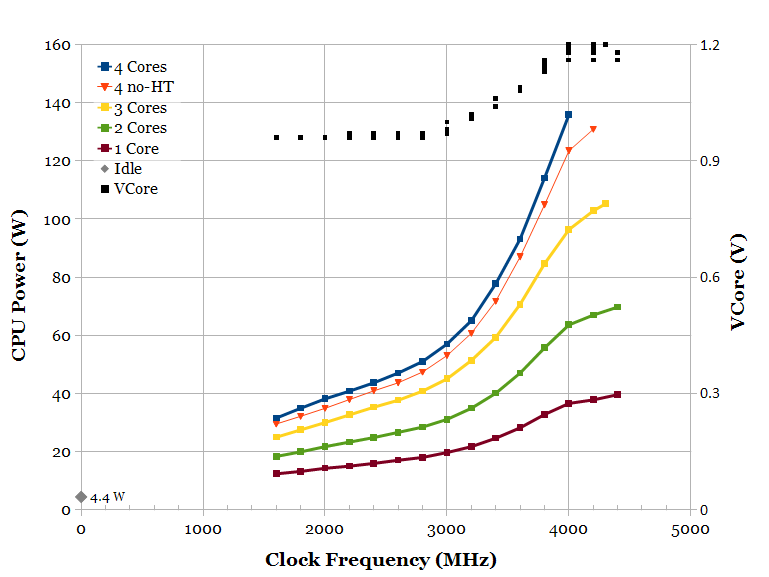
The problem with power is that both AMD and Nvidia (but specially nvidia) are pushing really hard for higher clocks, way past the point where the relation between clock and power scaling becomes exponential (example image bellow). You could decrease the clocks and voltages in order to lose 5% perf, and shave 1/3~1/4 of the power usage.
17 hours ago, linuxChips2600 said:Therefore, one of the ways that this problem has been combated so far is through the use of alternatives to x86-64, the biggest perhaps being the ARM architecture family.
No, the ISA has nothing to do with the process node, clock scaling and power consumption. The thing about an ARM x x86 design is how efficient you can make an specific use-case be, and how you can make proper use of the available transistor count for your µArch. Remember that the ISA is just a facade to your actual µArch, and that moderns high-end processors, be it ARM or x86, have some really similar design choices.
17 hours ago, linuxChips2600 said:Furthermore, Apple just demonstrated this past year that there's lots to be gained in both performance and power efficiency by switching over to a custom ARM architecture (although by how much is still disputable as Apple throttled pretty hard the Intel CPUs that they were putting onto their Mac-Minis and laptops).
It's hecking efficient due to the fact that it's built on a 5nm process, has tons of coprocessors (heterogeneous computing) in order to offload tasks from the CPU in a more efficient and faster way, and every component is tightly coupled. The CPU being based on an ARM ISA is just a pretty small detail when you consider everything, and I bet they would have achieved the same results (or even better!) with any other ISA.
17 hours ago, linuxChips2600 said:Furthermore, ARM has at least a reputation of being much more efficient than x86-64, especially with their widespread-use in high-performance smartphones such as the latest Samsung Android flagships and iPhone flagships. But the deeper I dove into the debate of x86-64 vs ARM efficiency, the more confused I got.
Efficiency it directly related to what task you need to do. In a phone, with basic media consumption and lots of hardware accelerators (reminder that a phone has a SoC with tons of other peripherals apart from the CPU), having a CPU that doesn't have tons of legacy hardware and specialized extensions (such as AVX2) surely helps since those aren't really used. When you got to anything more demanding/high performance, both ARM and x86 deliver pretty much the same performance and have a similar power consumption.
17 hours ago, linuxChips2600 said:However, here's also another 3 different articles/posts (including another post on this forum) that emphasize the specific micro-architectural design of the chips themselves rather than whether it's simply ARM vs x86-64 when it comes to efficiency, and even outright state that beyond a certain wattage limit both x86-64 and ARM exhibit very similar levels of efficiencies (even the webcodr.io website stated earlier somewhat acknowledges this as well):
YES. I totally agree with this point.
17 hours ago, linuxChips2600 said:So as the title states, my question really is - when it comes to maximizing performance/watt, is it much more about basically optimizing every layer of your "ecosystem" all the way from the hardware microarchitecture to the APIs, system applications, and even user applications themselves (kind of like how Apple has always done it especially with iPhones)
Yes!
17 hours ago, linuxChips2600 said:OR does using ARM in general truly have a performance/watt advantage over x86-64 which can be capitalized without sacrificing too much performance?
No, it doesn't, you're sacrificing lots of things and the actual µArch implementation is what matters. You mostly don't notice such sacrifices and think that ARM is pretty close in performance to x86 while having amazing power consumption because the µArch was tailored for such simple use-cases that you commonly see most ARM CPUs being used (as in, browsing facebook and watching youtube).
17 hours ago, linuxChips2600 said:computer architecture
Make sure to take a class into that, and read Patterson's book, it's amazing.

-
Topics
-
 0
0 -

Anonymous Reviews ·
Posted in Member Reviews0 -

SOROBIN ·
Posted in Graphics Cards5 -

OldFord76 ·
Posted in Troubleshooting1 -

Blawe17 ·
Posted in Troubleshooting2 -

Ronbaow ·
Posted in Troubleshooting1 -

zoneeye ·
Posted in Troubleshooting5 -

leclod ·
Posted in Operating Systems3 -

PatRed ·
Posted in New Builds and Planning6 -
 3
3
-
-
play_circle_filled

Latest From Linus Tech Tips:
He Spent 3 YEARS Begging me for a PC. Good Luck Finding it!














Create an account or sign in to comment
You need to be a member in order to leave a comment
Create an account
Sign up for a new account in our community. It's easy!
Register a new accountSign in
Already have an account? Sign in here.
Sign In Now