

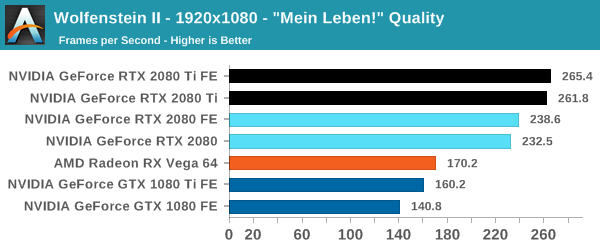
I'm very curious about this. While looking over some RTX 2080 benchmarks, I noticed the GeForce 20 series commands a hefty lead over the 10 series in Wolfenstein II:


The trend is similar even at 1440p or 4K
https://www.techpowerup.com/reviews/MSI/GeForce_RTX_2080_Ti_Lightning_Z/26.html
https://www.guru3d.com/articles-pages/geforce-rtx-2080-ti-founders-review,21.html
So what's the secret sauce here? 

-

-

It seems that it is using Vulcan API, and the new nvidia 2000 series finally support async compute, so they can utilize vulcan. If you see at the first picture, the Vega 64 is faster than the 1080ti.
-

So I dug around some more, and while I was inclined to throw in that it's just raw GPU power, I was looking at the 2080 Ti, not the 2080. You could easily explain the 2080 Ti's performance by the sheer number of shaders. But the 2080 has fewer shaders than the 1080 Ti (2944 vs 3840) and yet performs roughly between 1.35 and 1.48 times better.
I found a video showing the Titan V against the RTX 2080 Ti in Wolfenstein and the Titan V doing better:
So here's the conundrum, both Volta and Turing perform remarkably well in this game, but comparatively speaking, Vega 64 does not. This is not to knock on AMD, but it means there's something NVIDIA is doing that AMD isn't and Wolfenstein II uses. Also curiously, according to AnandTech about the quality preset they used:
QuoteThe highest quality preset, "Mein leben!", was used. Wolfenstein II also features Vega-centric GPU Culling and Rapid Packed Math, as well as Radeon-centric Deferred Rendering; in accordance with the preset, neither GPU Culling nor Deferred Rendering was enabled.
They didn't say Rapid Packed Math was disabled, which is a Vega feature. Though all this means is Vega can take its FP32 cores and do two FP16 operations at once. So does Turing support this? Yes, and in fact, at a 2x rate of FP32 performance according to NVIDIA's white paper. And while I can't find a primary source, Wikipedia says that Volta supports this as well, considering it lists the FP16 performance as 2x FP32.
Except it can't be this, otherwise Vega would've wiped the floor with Pascal, which Wikipedia lists Pascal can do about 1/2 FP32 performance when doing FP16 operations.
So then there's one other thing that makes Turing and Volta stand out from Vega and Pascal: Turing and Volta can do concurrent integer (INT) operations along with floating point (FP) ones. That is, in Turing and Vega, there are separate dedicated units for either INT or FP. In Vega and Pascal, the INT and FP units are together in a shader core so it can only do one or the other. On page 13 of the Turing whitepaper, there's a graph showing the potential performance uplift in games that use a mix of FP and INT.
To pick out an example, the whitepaper claims in Battlefield 1 (BF1) there's a potential of about a 1.5 performance uplift due to the mixed FP + INT operations. While Anandtech's benchmarks didn't show this, the Guru of 3D's BF1 benchmark showed something more interesting with the 1080 Ti getting 161 FPS and the 2080 getting 194 FPS, both at 1080p. Also do note that if we take shader count and clock speed, barring no other improvements, the 1080 Ti's raw FP32 performance is still 1.2 times better than the RTX 2080's. So on top of working on a 1.2 times deficit, the RTX 2080 is able to push out 1.2 times more FPS. I'm not sure what would cause this difference, considering AnandTech's machine is technically better
Given this, it might be reasonable to conclude that the separation of FP and INT operations in Turing and Volta is what's doing it.
To address the idea that asynchronous compute might have a factor, I doubt it. Improvements to asynchronous compute were not mentioned. I also would have expected Vega to have a significant lead over Pascal, but even in AMD's asynchronous compute poster child game Ashes of the Singularity, Vega 64 loses to the GTX 1080, if just barely. However, there is one thing that Volta did introduce that may affect compute workloads, by introducing a new execution model. So instead of doing this:

Volta does this:
Except this doesn't increase performance and graphics routines tend to be as predictable as possible.
tl;dr: I think the INT and FP execution unit separation is causing the performance uplift. The new execution model may be, but I can't see how.
-
Also please note that asynchronous compute is not an actual feature of nor is it required to use DX12 or Vulkan. All those API are doing is allowing the application to create multiple queues and letting the driver/hardware figure out how to distribute the workload rather than give the driver/hardware a single queue that may leave execution bubbles.
Basically, it doesn't make sense to say "Vulkan has better async compute support"



